RISCV向量指令集初探
本文基于PLCT实验室公开演讲内容
前言
RVV中有一些常用缩写词,看RVV spec时需要弄明白这些概念。部分摘自
https://www.cnblogs.com/sureZ-learning/p/18822201
以下列一下RVV中常见的单词缩写
| 单词缩写 | 全称 | 含义 |
|---|---|---|
| VLEN | Vector Length in bits | 向量寄存器长度,单位 bits |
| ELEN | Element Length | 最大元素宽度,单位 bits,常见的 ELEN=32 和 ELEN=64,即最大元素宽度就是 XLEN 值 |
| SEW | Selected Element Width | 被选中的元素位宽,见下文详细描述 |
| EEW | Effective Element Width | 与 SEW 类似,有效的元素位宽,用于向量操作数。对于加宽指令,目的数据元素的位宽会加宽一倍 |
| LMUL | Vector Length Multiplier | 寄存器组乘系数,表示一个寄存器组由多少个向量寄存器组成 |
| EMUL | Effective Element Width | 与 LMUL 类似,表示有效寄存器组乘系数,对于加宽指令,目的寄存器组乘系数会加宽一倍 |
| AVL | Application Vector Length | 应用程序向量长度,指的是应用程序希望处理的数据元素总数 |
| VL | Vector Length | 向量长度,vl(Vector Length)是一个关键的控制寄存器,RVV 并不是能设置 vl 寄存器的,而是将 AVL 参数传递给 vsetvl 指令来设置正确的 vl 值 |
几点提示:
-
由SEW,ELEN的解释不难推断出,在rvv中,寄存器中元素elements与位bits并不是一个东西,元素可以由vtype.vsew字段指定位宽。
-
XLEN和VLEN并不总是一样宽,VLEN是向量寄存器的位宽(由具体硬件决定),而XLEN是指当arch为rv32时,为32bits,当arch为rv64时,为64bits这种。
ELEN(Element Length)
规定了向量处理单元 (VPU)的最大长度,并且ELEN >= 8,且ELEN是2的幂,常见有ELEN = 32和64
VLEN
表示单个向量寄存器的位数,约束:VLEN≥ELEN,VLEN必须是2的幂,且VLEN <= 65536(即2的16次幂), 常见的VLEN= 128bits,256bits,512bits,1024bits等
VLEN在芯片设计时就确定下来了,怎么获取VPU的VLEN?直接读取vlenb 寄存器然后乘以8 即可(原因是vlenb 以 Bypte为单位,VLEN以bit为单位)
SEW
SEW 表示被选中的元素位宽,SEW可以取8/16/32/64
| SEW | 对应的C语言数据类型 |
|---|---|
| 8 | int8_t,uint8_t |
| 16 | int16_t,uint16_t, float16_t, bfloat16_t |
| 32 | int32_t,uint32_t, float32_t |
| 64 | int64_t,uint64_t, float64_t |
EEW
EEW表示有效的元素位宽,用于向量操作数,一般情况下EEW=SEW,但有些加宽指令中,数据元素的位宽会加宽一倍也即EEW=2 * SEW。
Q:什么是加宽指令? A:举个例子,两个32位的操作数经过运算得出64位的结果,操作数中的元素需要用32位一个来解析,但是结果的元素一个确有64位,这种就叫加宽指令,下文有更详细的例子。
比如rvv中vwadd 扩宽加为例,EEW=2 * SEW:
1
2
# Widening signed integer add/subtract, 2 * SEW = SEW + SEW
vwadd.vv vd, vs2, vs1, vm # vector-vector
LMUL
LMUL表示寄存器组乘系数,表示一个寄存器组由多少个向量寄存器组成,LMUL 可取值1/8,1/4,1/2, 1,2, 4,8 这并不意味着在什么情况下LMUL 都能取上述所有值之一,LMUL需要满足如下约束(第8讲5.1节有更详细的讨论):
1
ELEN * EMUL >= SEW
EMUL
EMUL表示有效寄存器组乘系数,一般情况下EMUL=LMUL,有些加宽指令中,元素的数量是一样的,所以对于目的操作数,寄存器组乘系数需加宽一倍。
SEW EEW LMUL EMUL 这四个参数有如下关系:
1
EEW/EMUL = SEW/LMUL
分为如下情况:
- 一般指令,
EEW=SEW且EMUL=LMUL - 加宽指令,对于源操作数:
EEW=SEW且EMUL=LMUL, 对于目的操作数:EEW=2 *SEW且EMUL= 2 *LMUL - 缩减指令,对于源操作数:
EEW=2 *SEW且EMUL= 2 *LMUL,对于目的操作数:EEW=SEW且EMUL=LMUL
举例:
以 A + B = C 向量扩宽加法举例:
A B 输入数据类型为int32,
C的数据类型为Int64
假设VLEN=128bits,那么一个向量寄存器可以放{a0~a3} 共4个元素,如果LMUL=2 时,意味着使用两个向量寄存器,一共可以装{a0~a7}共8个元素,此时EEW=SEW 且 EMUL=LMUL,向量B也是类似
对于输出C向量,数据类型为Int64,VLEN=128bits,那么一个向量寄存器可以放{c0~c1} 共2个元素,很明显2个寄存器存放不了8个int64 元素,所以LMUL也要扩宽,也即EEW=2 * SEW 且 EMUL= 2 * LMUL
1. RVV状态寄存器
1.1 mstatus
mstatus 是RISC-V 特权架构(Privileged Architecture) 的核心组成部分。特权架构是任何想要运行操作系统或需要不同权限级别管理的RISC-V处理器所必需的。所有符合RISC-V标准的处理器都必须实现机器模式(Machine Mode,M-mode),而 mstatus 正是机器模式下最重要的控制状态寄存器(CSR)之一。
它包含了处理器的当前运行状态,比如:
- 中断使能位
- 当前和之前的特权级别
- 浮点单元或向量单元的状态位(如我们之前讨论的 FS 和 VS)
- 其他一些控制位
其中的第 [10:9] 位用于反应向量状态,即 [10:9] 位用来表示VS(Vector Status,向量状态)字段。mstatus.VS就用来表示mstatus寄存器中VS字段的状态,VS一共两位,可以表示四个状态,分别如下
| mstatus[10:9] | VS Meaning | 作用 |
|---|---|---|
| 0 | Off | 表示向量指令集未被启用,尝试执行任何向量指令或访问向量 CSR(Control and Status Registers)将导致非法指令异常。 |
| 1 | Initial | 表示向量指令集处于初始状态,这意味着虽然尚未执行任何会改变向量状态的指令,但是可以开始执行这些指令。 |
| 2 | Clean | 表示向量指令集已经被使用过,但目前没有未保存的变化。如果执行了任何更改向量状态的指令,VS 会被自动设置为 Dirty。 |
| 3 | Dirty | 表示向量指令集已经被使用,并且存在未保存的变化。在这种状态下,必须保存向量寄存器内容才能安全地切换上下文。 |
- 在VS=Off状态,执行任何向量指令(包括访问向量CSR寄存器)将会导致非法指令异常;
- 在VS=Initial 或 Clean状态,执行任何向量指令(包括访问向量CSR寄存器)将会将VS状态置为VS=Dirty状态
- 当VS=Dirty时,这通常意味着需要保存向量寄存器的内容,以避免在上下文切换过程中丢失数据。一旦向量状态被正确保存,VS域可以被清零(软件手动清0),以便其他进程可以安全地使用向量资源。
VS 设置为0-3多个取值是一种软件优化。软件通常会根据VS不同的值来判断是否需要保存RVV上下文,以此来减少上下文交换开销。
1.2 sstatus
sstatus 寄存器 (Supervisor Status Register - 监管者状态寄存器)
sstatus寄存器与监管者模式(Supervisor Mode, S-mode)紧密相关。- S-mode 本身是RISC-V特权架构中定义的一个标准特权级别,但它对于一个具体的RISC-V处理器实现来说是 可选的。
- 如果一个RISC-V处理器实现了S-mode(例如,为了能够运行像Linux、FreeBSD这样的通用操作系统,这些操作系统通常运行在S-mode),那么
sstatus寄存器就是S-mode下必需的核心控制状态寄存器。 - 它包含了S-mode运行所需的状态信息,很多位实际上是
mstatus中对应位的一个子集或影子(shadow)。例如,它也包含中断使能位(SIE)、前一个特权级别(SPP)、以及FS和VS(如果相应扩展存在且对S-mode可见)等状态位。
sstatus寄存器中的向量上下文状态域位于sstatus[10:9],这个寄存器是mstatus寄存器VS域的映射,作用与mstatus寄存器VS域相同。
1.3 vsstatus
vsstatus 寄存器 (Virtual Supervisor Status Register - 虚拟监管者状态寄存器)
vsstatus与RISC-V的 Hypervisor(虚拟机监控器)扩展(H-extension)相关。其中也包含了一个VS字段,用于管理第二级虚拟化的向量状态。
1.4 vsstatus与mstatus
这两个寄存器用于给hypervisor提供支持。但我目前没明白流程是怎样的。貌似是检测到向量指令的时候检查对应的status位,判断是否需要进入trap,让hypervisor处理。
2. RVV CSR寄存器
这部分我们讨论RISCV向量扩展下多出来的一些东西。RVV 拥有独立的32个vector寄存器和7个CSRs寄存器。

首先是32个向量寄存器,每个寄存器的长度是VLEN(由硬件设计阶段就确定下来的常数)
2.1 vlenb寄存器
vlenb是一个CSR,指每个向量寄存器有多少byte,也就是$VLEN / 8$,
2.2 vl寄存器
用于指定我们希望元素(不是bits!!!)的操作个数(注意,这里的元素长度是由SEW指定的,比如一个寄存器位宽32,SEW被设定为了8,那么这个寄存器就有4个元素)。同样,这个寄存器也是只读的,它只能被vsetvl指令或者首次异常矢量加载指令(fault-only-first)更新。
1
0 <= vl < VLMAX // vlmax = LMUL * VLEN / SEW
2.3 vtype寄存器
vtype寄存器位宽为XLEN,也即当arch为rv32时,vtype为32bits,当arch为rv64时,vtype为64bits,其中8: XLEN-2 bits为0
vtype规定了系统如何解释寄存器中存放的内容。比如元素宽度(SEW字段,用于表示我们应该把多宽的位看作一个元素来处理)等
vtype中有几个字段,用处如下

以RV32为例,下图可以更清晰的反映出寄存器中的layout

2.2.1 vill
vtype寄存器是只读的,只能通过vset{i}vl{i}指令来设置。vtype寄存器中的vill位可以用于表示set的值是否合法(1为非法)。
2.2.2 vsew & vlmul
SEW = 8,16,32,64,determined by on vsew[2:0]目前只有4个取值,多出来的一位处于reserve的状态 LMUL=1,2,4,8,1/2,1/4,1/8,determined by on vlmul[2:0]
LMUL是组乘系数,表示一个寄存器组由多少个向量寄存器组成
如果LMUL >= 1时,那么就会将n个寄存器(n表示LMUL取值)看作一个组(group),操作的时候会把这个组当成一个寄存器一样操作
如果LMUL <= 1,则会将一个寄存器当作多个寄存器来用
但是注意!这并不意味着在什么情况下LMUL 都能取上述所有值之一,LMUL需要满足如下约束
ELEN * EMUL >= SEW

Q:大家看到这里不妨思考一下,为什么LMUL需要<1或是>1呢?
A:当你需要处理的向量中元素数量很多,或者每个数据元素本身很宽(例如
SEW=64位),单个物理向量寄存器可能不足以容纳一次操作想要覆盖的所有元素。所以通过设置LMUL > 1,可以将LMUL个相邻的物理向量寄存器逻辑上看作是一个单一的、更宽的逻辑向量寄存器。当你处理的数据元素本身很窄(例如
SEW=8位),单个物理向量寄存器可能包含远超当前算法实际需要的元素数量。所以我们通过切分实际上的物理寄存器,来达到增多逻辑上的寄存器,这样就可以节省资源。
2.2.3 vta,vma
这部分放在后面讲。涉及到掩码的知识。
2.4 vstart寄存器
这是一个用于异常处理的寄存器,一般情况下,vstart寄存器只能由硬件执行向量指令时写入,软件不需要管。举例:当硬件执行向量指令时遇到中断或异常,硬件可以将已经处理的元素索引写入vstart寄存器,等中断或异常处理完成后,将从vstart开始恢复处理
所有vector指令都是从vstart中给定的元素索引开始执行,并在执行结束时自动将vstart CSR重置为零。另外目的寄存器的0-vstart元素采取不打扰策略(即跳过索引小于vstart的那些元素)。
注意:所有向量指令,包括vset{i}vl{i},都将vstart CSR重置为零。应用程序不应该修改vstart,当vstart!=0时,一些向量指令可能会引发非法指令异常。
2.5 vxsat & vxrm & vcsr寄存器
vxsat:用于指示 向量定点指令 是否发生 饱和(saturation)
饱和 是指当固定点运算的结果超出目标格式的表示范围时,结果会被限制为该格式的最大或最小值(而非溢出)
例如:16 位有符号整数的最大值是 32767,若运算结果为 32768,则会饱和到 32767。
置1则表示饱和,方便程序员精准把控程序状态。
vxrm:控制定点运算的舍入模式(如四舍五入,截断等)
关键公式 无符号舍入:roundoff_unsigned(v, d) = (v » d) + r 有符号舍入:roundoff_signed(v, d) = (v » d) + r 其中 r 根据 vxrm 的模式计算。 示例 假设 v = 0b10110(二进制),d = 2(舍弃 2 位):
| rnu 模式 | v » 2 = 0b101,r = v[1] = 1 → 结果为 0b110(即 6)。 |
|---|---|
| rne 模式 | 若 v[d-1] = 1 且 v[d-2:0] = 0,则向偶数舍入;否则按 rnu 处理。 |
| rdn 模式 | 直接截断为 0b101(即 5)。 |
| rod 模式 | 若 v[d-1:0] ≠ 0,则加 1,结果为 0b110(即 6)。 |

vcsr:包含 vxrm 和 vxsat 的字段。它允许通过一条指令同时访问这两个状态信息。减小开销
| 位范围 | 字段 | 描述 |
|---|---|---|
| vcsr[2:1] | vxrm | 定点舍入模式(2 位) |
| vcsr[0] | vxsat | 定点饱和标志(1 位) |
3. RVV数据寄存器
RVV 有32个vector寄存器,编号v0-v31,每个寄存器的宽度是固定的,宽度为VLEN bits。

一个向量机器的向量寄存器中的元素通常分布在lanes上,具体在哪个lane中,是由 $第x个元素 \bmod \text{lane个数}$决定的,如上图所示共有8个lane,因为$9 \bmod 8 = 1$,所以放在Lane1中。寄存器中的Lane是为了并行的向处理器中的Lane提供元素,如下图所示
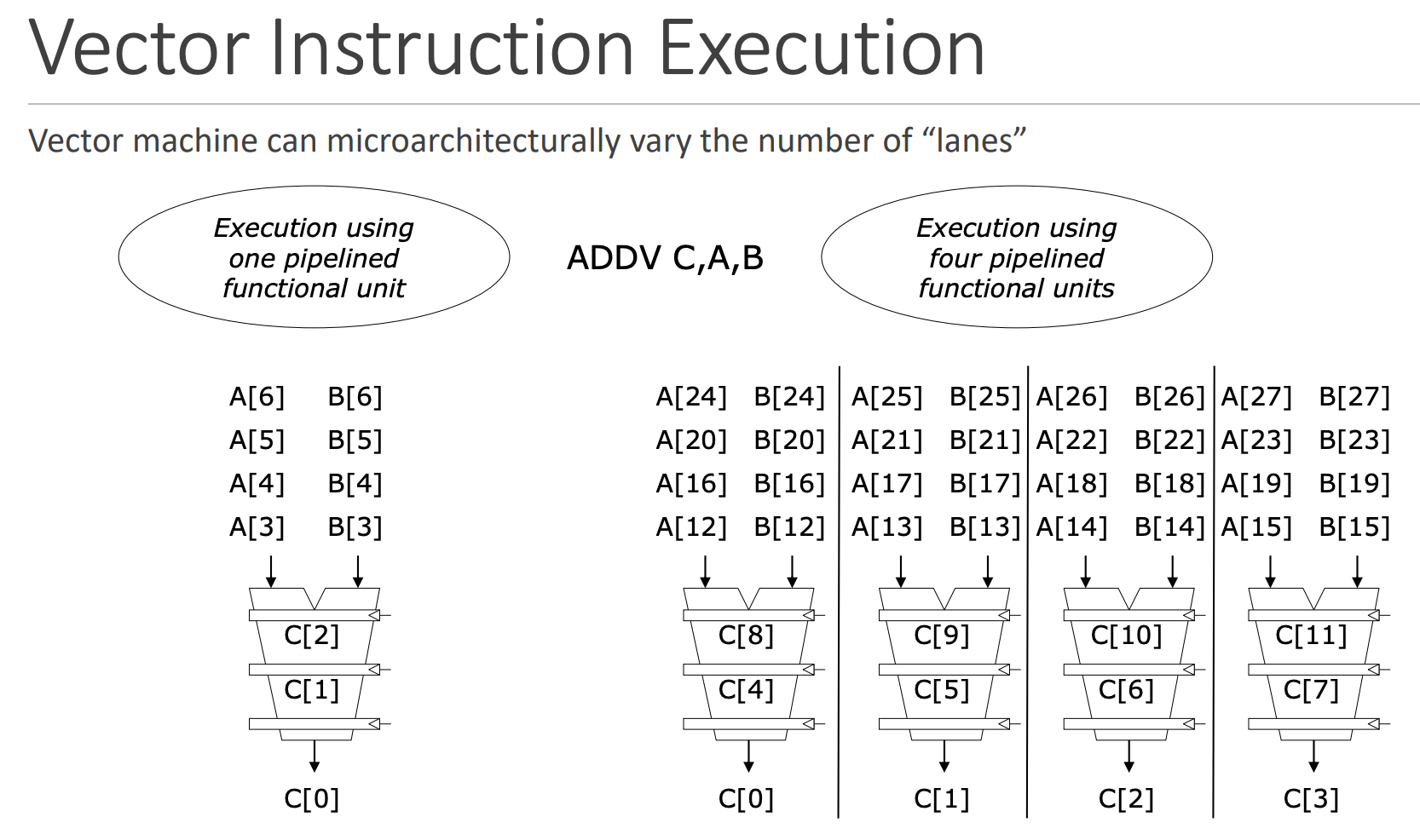
图片来源:CMU15-740
关于Lane,在向量处理器中并不少见,其用于增加指令的并行性。
想象一条有多个车道的高速公路。每条车道就是一个Lane。收费站(指令分发单元)给每条车道分配一批车(数据元素),这些车同时通过各自的车道(并行处理)。如果车流量大(长向量),每条车道可能需要分几批让车通过。有些特殊操作可能需要在不同车道之间换道(跨Lane通讯)。
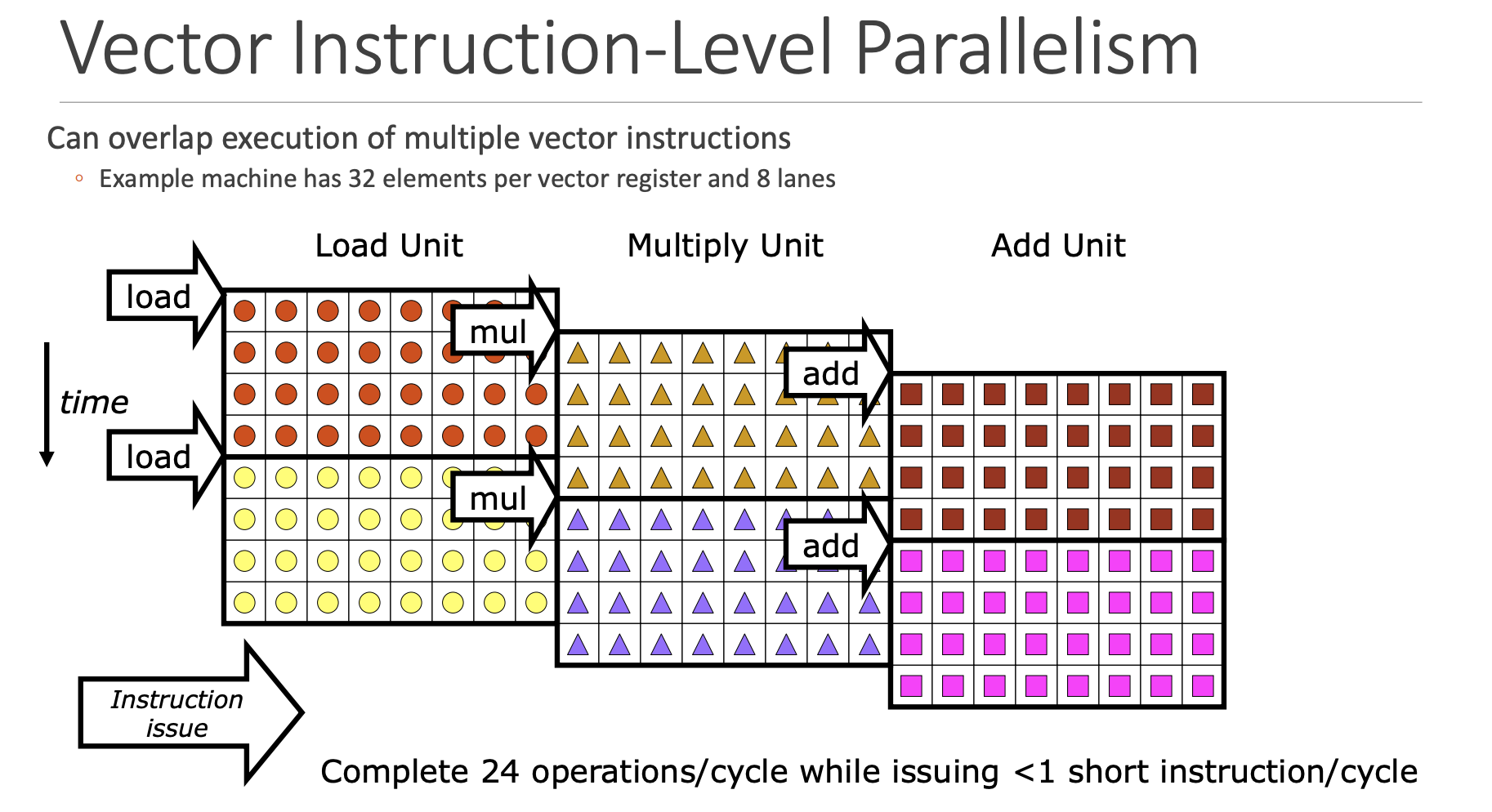
图片来源:CMU15-740
向量处理器不光能在单条指令内通过Lanes进行数据并行,也可以在不同向量指令间实行并行执行,也就是流水线的思想。
实际上,每个Lane就包含了多个vector unit。不过在rvv的学习中,我们并不需要关注这么多

图片来源:PLCT实验室公开演讲-罗云千-基础向量架构
4. 指令格式
4.1 load
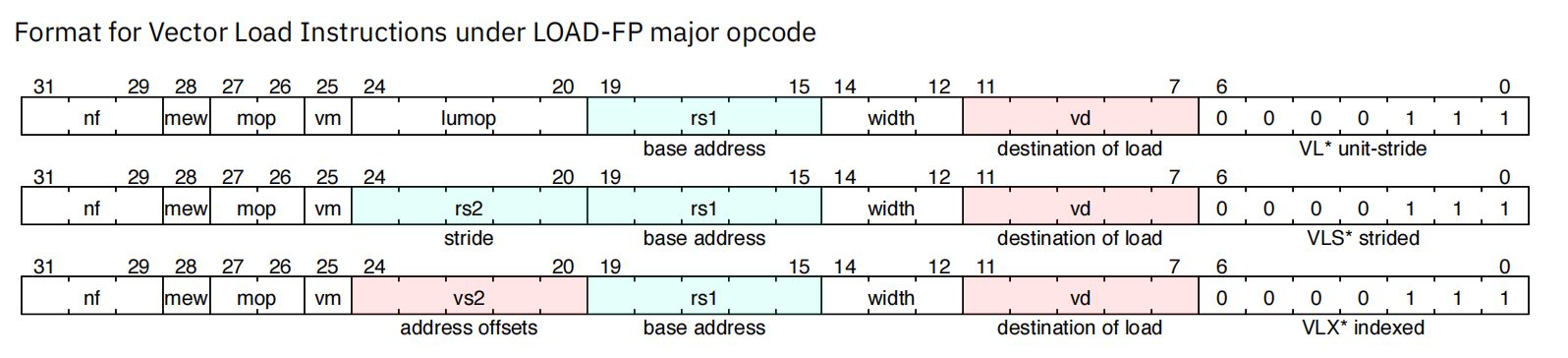
4.2 store
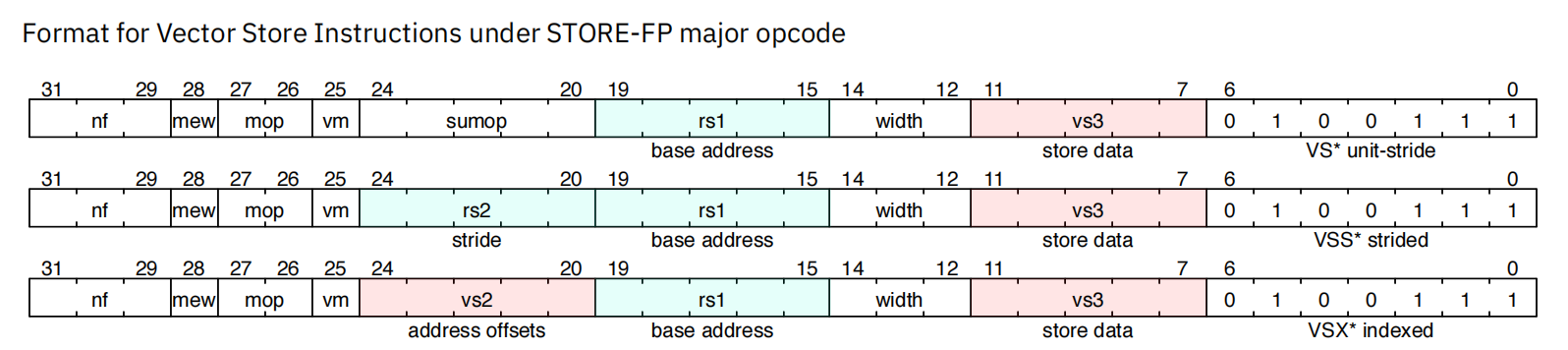
4.3 向量操作指令
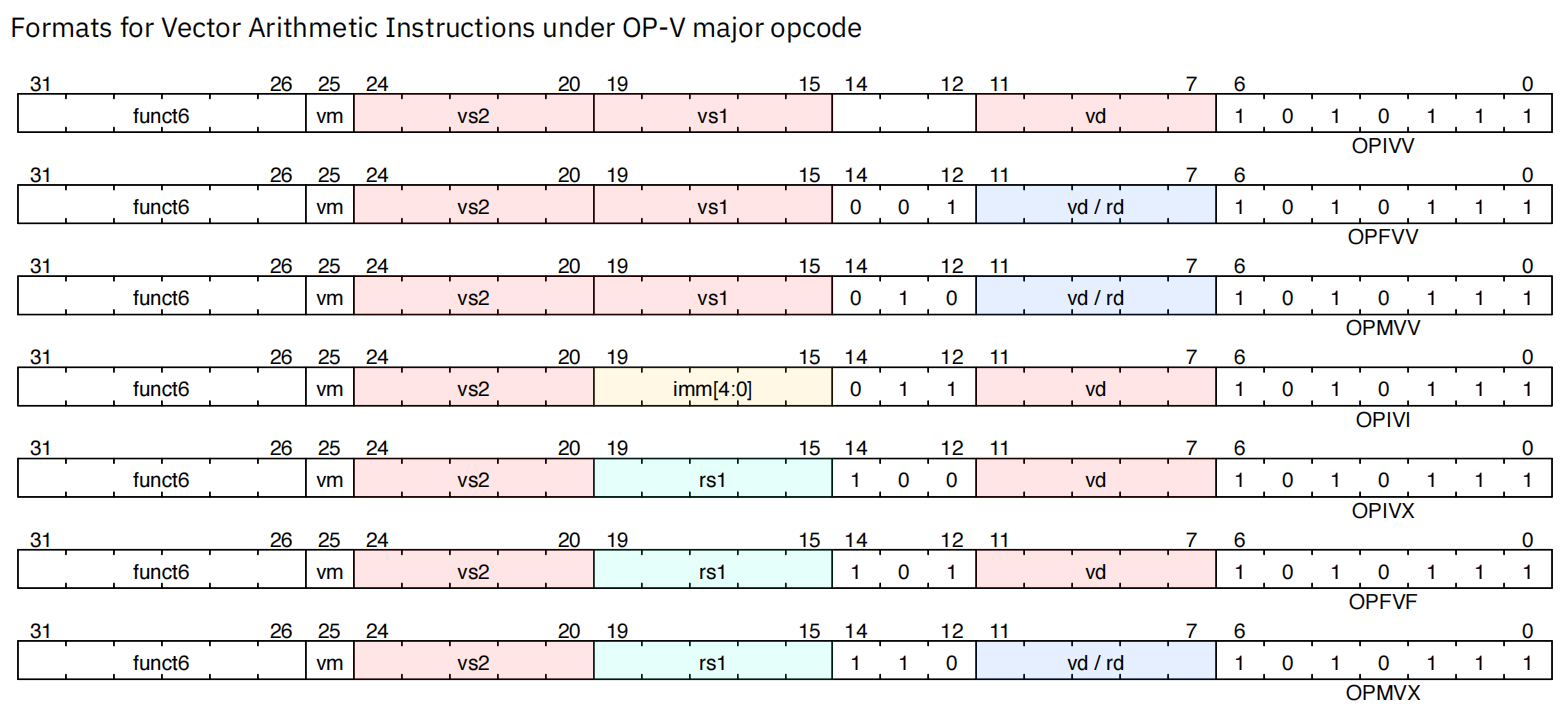
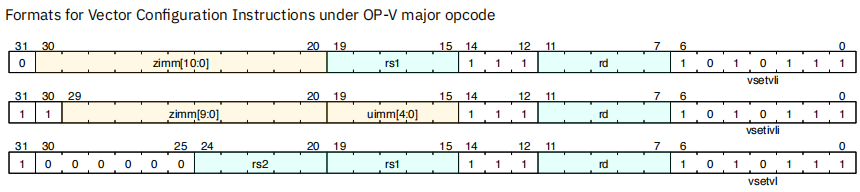
4.4 向量设置指令
掩码(Mask)
向量指令的第二十五位(vm字段)表示着掩码的开启与否。向量寄存器v0提供掩码值(即开启mask的话,无论SEW与LMUL如何总是用v0内的值作为掩码)
即,v0中的一个bit表示一个元素,并不与SEW对齐。在老的RVV Spec中,掩码是与SEW对齐的,有时会浪费大量空间(比如多寄存器的情况)。但是由于不是对齐的原因,有时mask与要操作的元素并不在一个lane中,这时就需要将mask broadcast进元素对应的lane中。
mask有很多种用法,比如,如果我们只想操作大于0的数,那么我们就可以先运行一个与0比较的操作,生成mask,在利用mask只对那些大于0的数进行操作。
很多指令都支持向量操作,比如
vadd.vv vd, vs1, vs2, vm
; Usage
vop.v* v1, v2, v3, v0.t # enabled where v0.mask[i]=1, vm=0
vop.v* v1, v2, v3 # unmasked vector operation, vm=1
v0.t 表示掩码,其中.t表示ture,当v0.mask[i] = 1,控制的第i个元素进行vop操作
如果没有v0.t掩码,表示不进行掩码操作(vm=1)
注意:当前的RVV只支持一个向量掩码寄存器v0
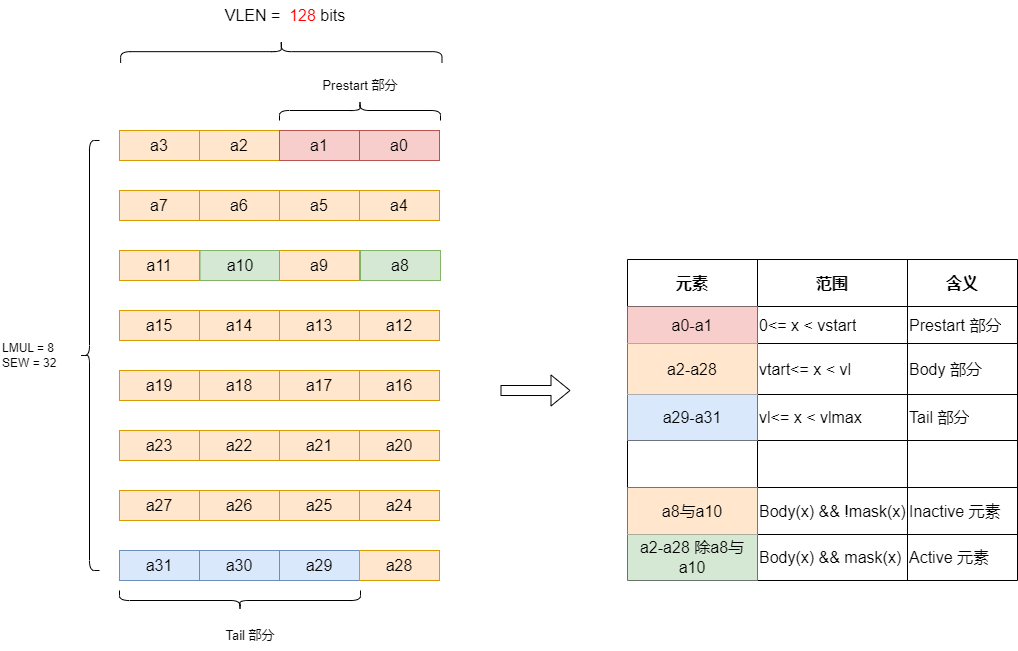
Prestart, Active, Inactive, Body, and Tail Element Denitions
概念

在向量指令执行期间,元素可以分为以下几类:
预启动元素(Prestart Elements):索引小于 vstart 的元素,不会引发异常,也不会更新目标寄存器。 活跃元素(Active Elements):当前向量长度(vl)内的元素,且掩码启用(参与计算)。 非活跃元素(Inactive Elements):当前向量长度内的元素,但掩码禁用(不参与计算)。 尾部元素(Tail Elements):超出当前向量长度(vl)的元素。
由图可知,active的条件是元素同时处于body中和mask中,向量操作只会更改active中的元素,不过rvv也保留了一些对inactive元素的可操作性。
回忆一下刚刚vtype中的两个字段vma和vta,这两个字段就是为mask和tail段的元素提供灵活的修改可能性。
vta 和 vma 的组合定义了四种处理策略:
| vta | vma | 尾部元素(Tail) | 非活跃元素(Inactive) | 说明 | | — | — | ———– | ————— | ——————- | | 0 | 0 | undisturbed | undisturbed | 所有未参与元素保留原值 | | 0 | 1 | undisturbed | agnostic | 尾部元素保留原值,非活跃元素可自由处理 | | 1 | 0 | agnostic | undisturbed | 尾部元素可自由处理,非活跃元素保留原值 | | 1 | 1 | agnostic | agnostic | 所有未参与元素可自由处理 | agnostic:元素可以保留原始值,或被覆盖为全 1(硬件自由选择) agnostic:元素可以保留原始值,或被覆盖为全 1(硬件自由选择)
从 RISC-V Vector v0.9 起,vsetvli 指令必须显式指定 vta 和 vma 的设置。语法如下
vsetvli t0, a0, e32, m4, ta, ma # Tail Agnostic, Mask Agnostic
vsetvli t0, a0, e32, m4, tu, ma # Tail Undisturbed, Mask Agnostic
vsetvli t0, a0, e32, m4, ta, mu # Tail Agnostic, Mask Undisturbed
vsetvli t0, a0, e32, m4, tu, mu # Tail Undisturbed, Mask Undisturbed
一个例子
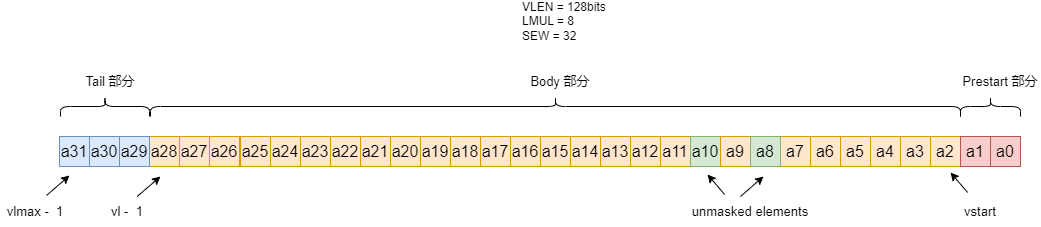
举例:VLEN = 128 bits,当元素类型为int32_t时,每个RVV寄存器可以装4个元素(VLEN / SEW), LMUL 可以取{1/4,1/2,1,2, 4, 8}(为什么LMUL不能取1/8 ,1/4? 这是因为ELEN EMUL 与 SEW要满足约束:ELEN * EMUL >= SEW,即EMUL >= SEW / ELEN = 32/64 = 1/2),所以vlmax = LMUL* VLEN/SEW
如图所示
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
VLEN = 128 bits
SEW = 32
LMUL = 8
vstart = 2
所以:
Prestart部分[a0,a1]
Body部分 [a2,a28]
Tail部分 [a29, a31]
其中Body部分,可以设置一部分参与运算,一部分不参与运算
Inactive 元素,a8与a10, 不参与运算
Active 元素,a2-a28除a8与a10, 参与运算
vset
vset的三个变种,分别是vsetvli,vsetivli, vsetvl
区别应该是使用寄存器还是立即数作为命令中的参数。

指令格式

vtype中的字段在前文也提到过。

Reference
https://www.cs.cmu.edu/afs/cs/academic/class/15740-f19/www/lectures/14-vector.pdf
http://staff.ustc.edu.cn/~comparch/25spring_slides/chapter06-1-Vector.pdf
https://www.bilibili.com/video/BV1vL411j7PV/?spm_id_from=333.1387.search.video_card.click&vd_source=a050735bf251f44101103e1314e38fe9
https://www.bilibili.com/video/BV1Zg411w7H2?spm_id_from=333.788.recommend_more_video.14&vd_source=a050735bf251f44101103e1314e38fe9
https://github.com/plctlab/PLCT-Open-Reports/blob/master/slides/20211211-rvv.pdf
https://www.cnblogs.com/sureZ-learning/category/2453794.html