CS61C|Lec18-IO
CPU与外界交互的方式是通过I/O接口
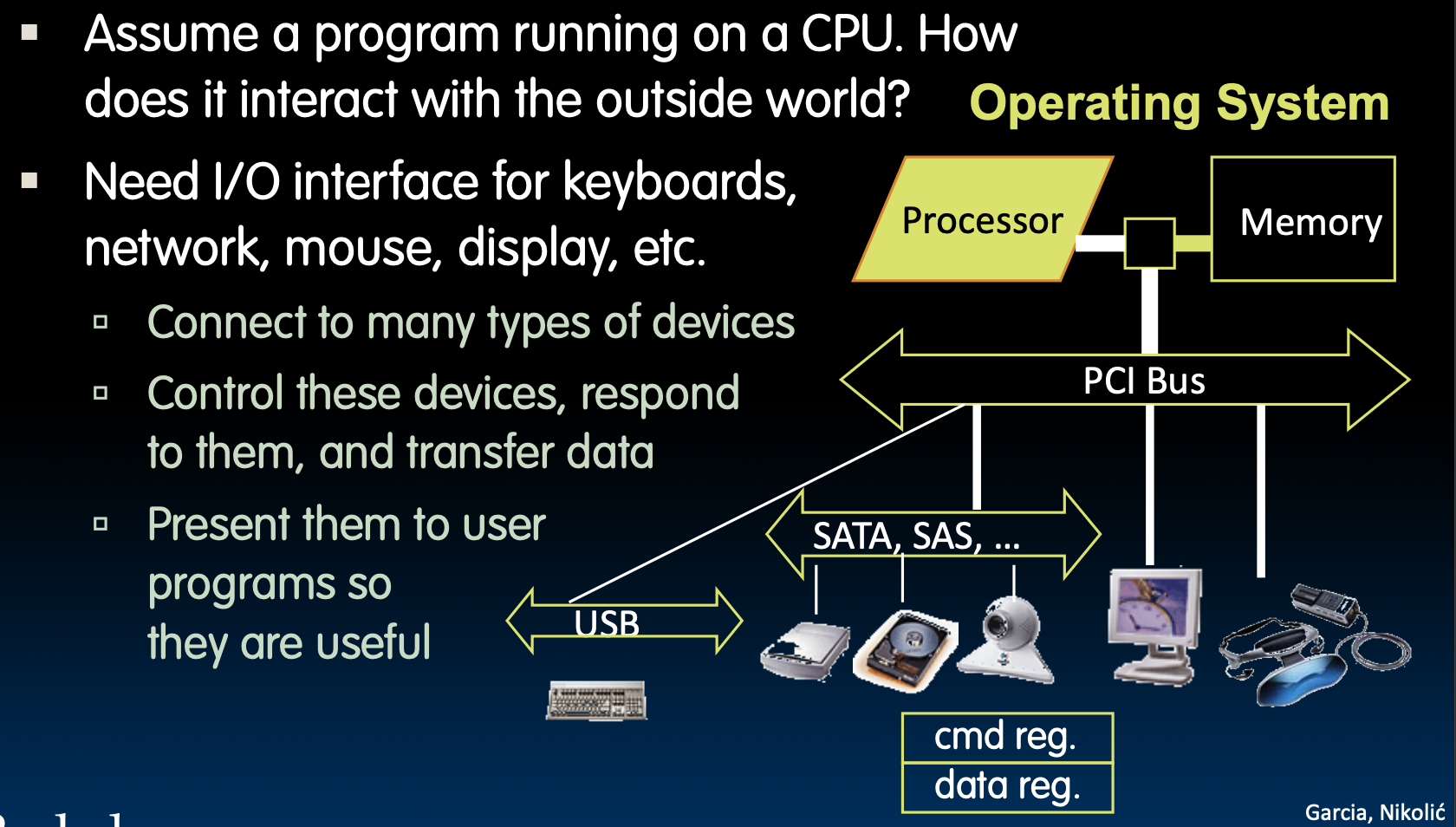
如何实现I/O接口呢
方法一:
使用特殊的输入输出指令和对应的硬件设计
方法二:
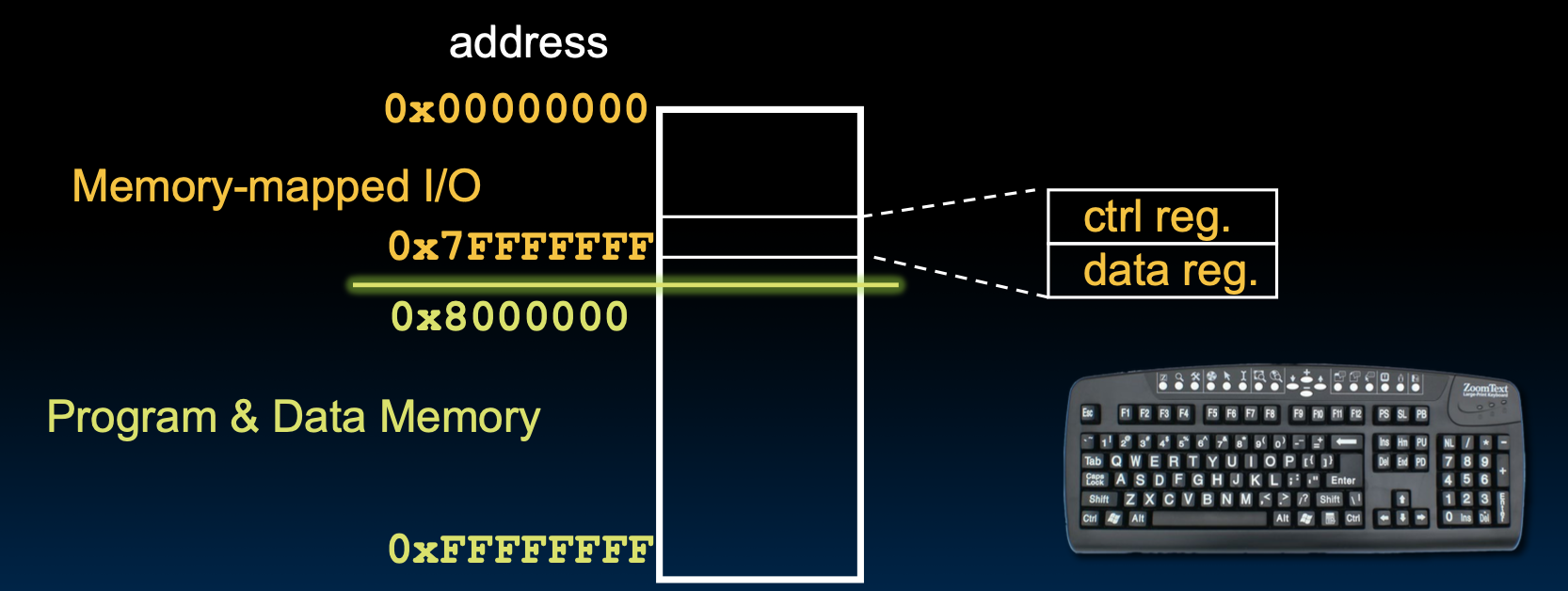
内存映射I/O(Memory-Mapped I/O)
-
定义:将I/O设备的寄存器映射到处理器的地址空间中,形成一个特定的地址范围用于I/O操作。
-
操作方式:
-
使用普通的加载(load)和存储(store)指令(例如
lw和sw)访问I/O设备。 -
通过访问特定的地址来与I/O设备进行通信。
-
-
优点:
-
统一的地址空间,简化了指令集(只需要加载和存储指令)。
-
可以利用现有的内存访问机制,简化了硬件设计。
-
更容易实现DMA(直接内存访问)等高级特性。
-
-
缺点:
-
可能会消耗一部分内存地址空间,限制可用内存的总量。
-
需要处理I/O设备的状态和控制寄存器,可能会增加复杂性。
-
内存映射I/O
一些特殊的地址用来干一些特殊的事情,比如:
轮询(Polling)
- 设备寄存器的作用
I/O 设备通常会有两个主要寄存器:
-
控制寄存器(Control Register):表示设备是否准备好进行读写操作。类似于一个信号员,它告诉处理器设备当前的状态,是否可以进行数据传输。
-
数据寄存器(Data Register):存储设备上的数据,处理器可以从这个寄存器中读取输入数据,或将数据写入其中以传送给设备。
- 轮询过程
轮询的过程就是处理器不断检查控制寄存器的状态,直到设备准备好,具体步骤如下:
-
读取控制寄存器:处理器会反复读取控制寄存器,检查“就绪位”(Ready bit)的状态。
-
当“就绪位”为 0 时,表示设备还未准备好,处理器会继续等待。
-
当“就绪位”从 0 变为 1 时,表示设备已经准备好,处理器可以进行接下来的操作。
-
-
执行 I/O 操作:
-
如果是输入操作(读取数据),处理器从数据寄存器读取数据。
-
如果是输出操作(写入数据),处理器将数据写入数据寄存器。
-
-
重置控制寄存器:I/O 操作完成后,设备会将控制寄存器的“就绪位”重置为 0,表示当前操作已完成,处理器需要等待下一次操作。
轮询的例子
- 输入(从键盘读数据)
1
2
3
4
5
6
lui t0, 0x7ffff # 加载 I/O 地址 7ffff000 到寄存器 t0
Waitloop:
lw t1, 0(t0) # 读取控制寄存器的值到 t1
andi t1, t1, 0x1 # 检查就绪位 (Ready bit),即 t1 & 1
beq t1, zero, Waitloop # 如果就绪位为 0,继续等待
lw a0, 4(t0) # 读取数据寄存器中的数据到 a0
-
lui t0, 0x7ffff:将 I/O 设备的基地址 0x7ffff000 加载到寄存器 t0。
-
Waitloop:轮询等待环节。在循环中,通过 lw t1, 0(t0) 从 I/O 控制寄存器读取设备状态,检查其是否已经准备好。使用 andi t1, t1, 0x1 提取出“就绪位”。
-
beq t1, zero, Waitloop:如果“就绪位”为0(设备未准备好),继续在 Waitloop 循环等待。
-
lw a0, 4(t0):当设备准备好后,从数据寄存器读取键盘输入,保存到寄存器 a0 中。
为什么要用lui加载地址?
- 输出操作(向显示器写入数据)
1
2
3
4
5
6
lui t0, 0x7ffff # 加载 I/O 地址 7ffff000 到寄存器 t0
Waitloop:
lw t1, 8(t0) # 读取控制寄存器的值到 t1
andi t1, t1, 0x1 # 检查就绪位 (Ready bit),即 t1 & 1
beq t1, zero, Waitloop # 如果就绪位为 0,继续等待
sw a1, 12(t0) # 将 a1 中的数据写入显示设备的数据寄存器
-
lui t0, 0x7ffff:同样地,将 I/O 设备的基地址加载到 t0。
-
Waitloop:同样通过轮询读取控制寄存器 lw t1, 8(t0),等待显示设备准备好接收数据。
-
sw a1, 12(t0):当设备就绪时,将 a1 寄存器中的数据写入显示设备的数据寄存器 12(t0)。
轮询的开销
假设一个处理器的参数如下
- 1 GHz 时钟频率
- 这意味着处理器每秒可以执行 10亿次(10^9)时钟周期。
- 每次轮询操作需要 400 个时钟周期
- 包含调用轮询例程、检查设备状态以及返回。
问题:在给定情况下,处理器在轮询上花费的时间百分比是多少?
我们将以下场景代入计算:
轮询鼠标
- 假设轮询的设备是鼠标,轮询频率为 每秒 30 次,为了确保不会漏掉鼠标的任何移动(避免光标在屏幕上的卡顿)。
- 每秒钟轮询次数:
每秒轮询 30 次,因此处理器每秒执行 30 次轮询操作。
- 每次轮询操作的时钟周期数:
每次轮询需要 400 个时钟周期,因此每秒轮询所花费的时钟周期总数为:
$30 \, \text{次/秒} \times 400 \, \text{时钟周期/次} = 12000 \, \text{时钟周期/秒}$
- 处理器每秒执行的总时钟周期:
处理器的时钟频率为 1 GHz,即处理器每秒可以执行 10^9(十亿)个时钟周期。
- 轮询开销的时间百分比: 我们需要计算在总时钟周期中,轮询所占的比例:
$\frac{12000 \, \text{时钟周期/秒}}{10^9 \, \text{时钟周期/秒}} \times 100\% = 0.0012\%$
轮询硬盘
轮询硬盘的频率 = $\frac{16 \, \text{MB/s}}{16 \, \text{B/轮询}} = 1,000,000 \, \text{轮询/秒} \, \text{(1百万次轮询/秒)}$
步骤 2:轮询所需时钟周期
每次轮询需要 400 个时钟周期。因此,轮询硬盘每秒所需的总时钟周期为:
$1,000,000 \, \text{轮询/秒} \times 400 \, \text{时钟周期/轮询} = 400,000,000 \, \text{时钟周期/秒}$
步骤 3:计算处理器时间百分比
处理器的时钟频率为 1 GHz,即 10亿时钟周期/秒。轮询硬盘所需的时钟周期占处理器总时钟周期的百分比为:
$\frac{400,000,000 \, \text{时钟周期/秒}}{1,000,000,000 \, \text{时钟周期/秒}} \times 100\% = 40\%$
轮询硬盘占用了处理器 40% 的时间,显然这是不可接受的,因为这意味着处理器的大量时间都花费在等待 I/O 操作上,而不能有效执行其他任务。此外,这个例子也指出了数据以 小块传输 形式处理的低效性,这也是问题的一部分。
I/O中断
轮询效率很低,因为不管有没有数据传输过来,我们都要去检查控制位。就像你家在开派对,你设置了一个计时器,隔一段时间就要去看看门口有没有人要进来一样低效。所以我们应该安装一个门铃!
那么在计算机中的门铃就是中断。
-
中断的工作机制
-
中断定义:当I/O设备准备好或者需要处理时,它向处理器发出一个信号,叫做中断。处理器会暂停当前程序的执行,转到操作系统的中断处理程序(trap handler)。
-
优势:
-
没有I/O活动时,处理器不会浪费时间。
-
中断只在必要时才触发,有效利用资源。
-
-
缺点:在频繁的I/O活动下,过多的中断会导致高昂的成本,比如影响缓存、虚拟内存的使用以及状态的保存和恢复。
-
-
适合中断的场景
-
低数据速率设备(如鼠标、键盘):
-
适合使用中断,因为这些设备的数据量很小,中断的开销也低。
-
可以使用定时器中断来轮询,但这种情况下中断机制足够高效。
-
高数据速率设备(如网络、硬盘):
-
初始时可以使用中断来检测数据是否到达。
-
一旦有大量数据到来,直接内存访问(DMA) 可以介入,将数据直接传输到内存,避免频繁的中断和处理器干预。
- 直接内存访问(DMA Direct Memory Access)
- 在大量数据传输时,中断机制会切换为DMA,以减少处理器干预。DMA 允许数据在I/O设备和内存之间直接传输,从而提高效率。
Direct Memory Access(DMA)
DMA (Direct Memory Access) 允许 I/O 设备直接与主存进行数据交换,而无需处理器的过多干预。这极大提高了高数据速率设备的效率,尤其是在大量数据传输时。下面是 DMA 的工作机制及其关键组成部分:
- DMA 引擎
-
DMA 引擎是一个专门的硬件组件,它负责管理 I/O 设备和主存之间的数据传输。
-
DMA 引擎通过一组寄存器与 CPU 进行交互,这些寄存器由 CPU 设置,指定传输的详细信息。
- DMA 寄存器的功能
-
内存地址(Memory address):指定数据要存放或读取的内存地址。
-
传输字节数(# of bytes):指定需要传输的数据量(以字节为单位)。
-
I/O 设备号(I/O device #):指示哪个设备将进行数据传输。
-
传输方向(Direction of transfer):指定是从 I/O 设备向内存传输数据,还是从内存向 I/O 设备传输数据。
-
传输单元(Unit of transfer):指定每次传输的数据块大小。
-
传输突发量(Amount to transfer per burst):定义每次传输的突发量,即在一次传输周期内移动的最大数据量。
-
DMA 的工作流程
-
CPU 设置 DMA:CPU 首先配置 DMA 引擎的寄存器,指定数据传输的参数(内存地址、传输字节数等)。
-
DMA 传输:DMA 引擎接管传输过程,直接在内存和 I/O 设备之间进行数据传输,而不需要处理器的干预。
-
完成传输:传输完成后,DMA 通知处理器,表明数据传输已经完成。

- DMA 的优势
-
降低处理器负载:DMA 减少了处理器在大数据传输过程中的干预,腾出处理器资源去处理其他任务。
-
提升传输效率:直接在内存和 I/O 设备之间进行数据传输,避免了轮询和过多中断造成的开销。
这种机制尤其适合像硬盘、网络等需要传输大量数据的设备,极大提高了系统性能。
打个比方,你开个面粉厂,每天要给不同大小的货车搬不同量的面粉放在货车上,后来干大了,你觉得你有更重要的事要做,所以你找了个傻子小弟,小弟只知道你发出的指令,从哪搬,搬多少,你说了他就照这个办。
DMA 传输的两种情况:输入与输出
-
DMA:输入数据的流程
-
设备发出中断信号:当设备有数据准备好时,它向 CPU 发送中断信号。
-
CPU 响应中断并启动传输:CPU 响应中断信号,指示 DMA 引擎或设备将数据放置在特定的内存地址。
-
DMA 进行传输:DMA 引擎或设备负责实际的数据传输,期间 CPU 可以继续执行其他任务。
-
传输完成,中断 CPU:当传输完成时,DMA 或设备再次中断 CPU,通知传输已完成。
-
DMA:输出数据的流程
-
CPU 决定开始传输:CPU 检查外部设备是否准备好接收数据。
-
CPU 开始传输:CPU 指示 DMA 引擎或设备,告知特定内存地址有数据准备好传输。
-
DMA 进行传输:DMA 引擎或设备处理数据传输,CPU 仍然可以执行其他任务。
-
传输完成,中断 CPU:DMA 或设备传输完成后,再次中断 CPU,通知任务完成。
DMA 引擎插入内存层次结构中的问题
DMA 引擎在内存层次结构中的插入位置会对系统性能产生影响,以下是两个极端位置:
- 在 L1 缓存和 CPU 之间
-
优点:这种方式可以保证数据的一致性(缓存一致性问题会自动解决)。
-
缺点:可能会污染 CPU 的工作集,将传输的数据加载到 CPU 缓存中,导致缓存失效和性能下降。
- 在最后一级缓存和主内存之间
-
优点:不会影响 CPU 的缓存,不会污染缓存数据。
-
缺点:需要手动管理数据一致性,处理起来较为复杂。